
Batch?
배치는 일정 시간 동안 대량의 데이터를 한번에 처리하는 방식을 의미한다.
Spring Batch?
spring Batch는 대량의 데이터를 처리하기 위한 프레임워크이다.
Batch Processing 즉 반복 일괄 처리 작업을 효율적으로 처리할 수 있는 기능을 제공한다.
대량의 데이터를 한번에 처리 하는 중간에 프로그램이 멈출 수 있는 상황이 존재한다.
상황을 대비하여 안전 장치를 마련해야하기 때문에 프레임워크를 사용하게 된다.
예를 들어 50만개의 데이터를 복잡한 JOIN 연산을 걸어 DB간 이동 시키는 도중 프로그램이 멈춰버리면 어떻게 될까 ?
처음부터 다시 시도한다면 시간 낭비, 자원 낭비이다.
따라서 처음부터 다시 시작할 수 없기 때문에 작업 지점을 기록해야한다.
이런 다양한 상황들을 대비할 수 있게 효율적으로 도와주는 것이 Spring Batch라고 보면 된다.
Spring Batch 특징
- 대량 데이터 처리
- Batch라는 이름에 맞게 충실히 데이터를 처리한다. 데이터 처리 작업을 분산 처리 할 수 있어 대량 데이터 처리 작업에 적합하다.
- 트랜잭션 관리
- 데이터 처리 중 실패한 작업은 롤백하여 데이터 일관성을 유지할 수 있다.
- 재시도 가능
- 중간 실패의 경우 작업을 재시도 할 수 있는 제공을 제공하며, 재시도 횟수도 설정할 수 있다.
Spring Batch 에서 중요한 부분
Batch 데이터를 효율적으로 빠르게 처리하는 것도 중요하지만, 내가 하고 있는 작업을 어디 까지 진행했는지 파악하고 이미 했던 일을 중복해서 하지 않게 (스케쥴러에 잡혀 실행 되기 때문에 중복 발생 가능성이 있음) 파악하는 것이 가장 중요하다.
즉 중복이나 놓치는 부분을 파악하기 위해 기록 하는 부분이 아주 중요하다.
Spring Batch 의 흐름
간단하게 읽어오기, 처리하기, 쓰기 를 읽어올 데이터가 없을 때 까지 무한 반복합니다.
읽어올 데이터가 없을 때 까지 라는 말에 의문을 가질 수 있습니다.
배치 작업을 할 때는 모든 데이터를 읽어와서 처리하는 것이 나눠서 처리하기 때문입니다.
예를 들어 100만개의 데이터를 읽고 처리하고 쓰는 것이 아닌 50개 씩 끊어서 일고 처리하고 쓰는것이라고 보면 된다.
나눠서 작업하는 것에 대해 이해를 위해 아래 모식도를 확인하자.

100만개 데이터를 옮기기 위해 50개를 처리하고 다시 50개를 처리하고 읽을 데이터가 없을 때 까지 진행 하는 것 이다. 읽기 처리 쓰기 전체가 50개를 처리 하기 위한 하나의 작업으로 보면 된다.
읽기 처리 쓰기를 하나의 처리 작업 (처리자)로 본다면 아래와 같은 모식도라고 보면 된다.

결론적으로 왜 배치작업을 위해 대량 데이터를 나눠서 읽어 작업하는 것일까 ?
한번에 많은 양을 읽어 버리면 메모리에 올리지 못하거나, 실패 했을 때 위험성이 크고 속도적인 문제도 발생하기 때문이다.
메타 데이터
위의 작업을 진행하면 데이터를 나눠서 읽어야하고, 다양한 작업 중 변수를 방지하기 위해서 기록을 해야 할 것 이다.
다양한 변수에 따라 시간적, 자원적 문제들이 생기겠지만 중복 문제 또한 기업에 입장에서는 상당히 큰 문제로 다가 올 수있다.
예를 들어 급여나 은행 이자 시스템의 경우 특정 일 에 처리하게 되는데 했던 처리를 또 하게되어 문제가 있을 수 있다.
다른 예시로 구독 서비스와 같은 경우에 주기별로 권한이 변경이 필요하지만 처리 중간에 문제로 권한 변경에 차질이 생기면 그것도 문제가 될 것 이다.
따라서 여기서 말하는 메타데이터란 배치에서 내가하고 있는 작업, 했던 작업을 기록하는 테이블이라고 보면 된다.
통상 메타데이터라는 호칭을 쓴다.
메타데이터 테이블
배치에서 중요한 작업에 대한 트래킹을 수행하는 테이블로, Spring Batch도 역시 메타데이터를 관리를 진행 해야합니다. 보통은 DB 테이블에 저장하며 application.properties, application.yml에 변수 설정시 해당 테이블 세팅이 등록된 위치의 @Primary로 설정한 테이블에 자동 생성을 진행할 수 있다.
// application.properties
spring.batch.jdbc.initialize-schema=always
spring.batch.jdbc.schema=classpath:org/springframework/batch/core/schema-mysql.sql테이블 스크립트 경로는 External Libararies > Gradle: org.springframework.batch:spring-batch-core:버전 > org.springframework.batch.core 에서 확인할 수 있다.
아래의 메타테이블은 자동생성된 테이블을 추출하여 확인한 ERD이다.

Spring Batch 내부 구조
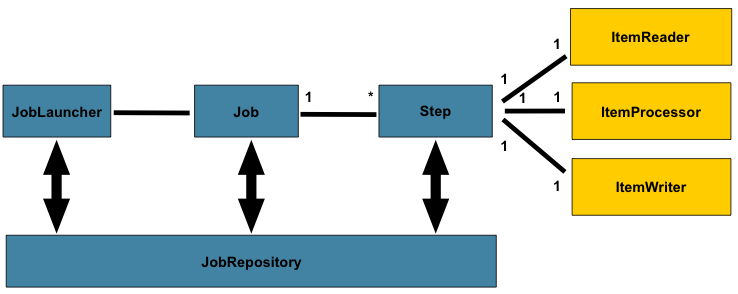
JobLauncer
- 하나의 배치 작업(Job)을 실행 시키는 시작 점
- Job을 실행하는 인터페이스이며 Job을 실행하기 위해서는 JobLauncer를 총해 Job을 실행해야한다.
Job
- 읽기 → 처리 → 쓰기 과정을 정의한 배치 작업
- Job은 하나 이상의 Step을 가지며, 하나의 배치 작업을 나타낸다.
Step
- Step은 배치 처리 작업의 최소 단위이며 하나의 트랜잭션에서 수행되는 단순한 작업의 Tasklet, 트랜잭션 범위 내에서 청크 단위로 데이터를 읽어 처리하는 방식은 Chunk 방식이 있다.
- 실제 하나의 읽기 → 처리 → 쓰기 작업을 정의한 부분으로, 1개의 Job에서 여러 과정을 진행할 수 있기 때문에 1 : N의 구조를 가진다.
JobRepository
- 얼만큼 했는지, 특정 일자 배치를 이미 했는지 “메타 데이터”에 기록하는 부분으로 Job과 관련된 정보를 저장하고 조회하기 위한 인터페이스이다.
- JobInstance(Job의 실행을 나타내는 인스턴스), JobExecution(JobInstance의 실행 정보), StepExecution(Step 실행 정보) 등이 포함된다.
ItemReader
- 읽어오는 부분
ItemProcessor
- 처리하는 부분
ItemWriter
- 쓰는 부분
Spring Batch의 JPA 성능 문제
Spring Batch의 read와 write 부분을 JPA로 구성 할 경우 JDBC 대비 처리 속도가 엄청나게 저하된다.
Batch에 있어서 Reader부분은 큰 영향을 미치지는 않지만 Writer의 경우 엄청난 영향을 끼친다.
성능저하가 일어나는 이유는 무엇일까?
Entity의 id 생성 전략은 보통 IDENTITY로 설정 하게 된다. save() 수행시 DB 테이블을 조회하여 가장 마지막 값보다 1을 증가 시킨 값을 저장하게 된다.
여기서 Batch 처리 청크 단위 bulk insert 수행이 무너지게 된다.
JDBC 기반으로 작성하게 된다면 청크로 설정한 값이 모이게 되고 bulk 쿼리로 단 1번의 insert가 수행되지만
JPA의 IDENTITY 전략 때문에 bulk 쿼리 대신 각각의 수만큼 insert 가 수행이 된다.
// JPA 예시
@Bean
public RepositoryItemWriter<AfterEntity> afterWriter() {
return new RepositoryItemWriterBuilder<AfterEntity>()
.repository(afterRepository)
.methodName("save")
.build();
}
// JDBC
@Bean
public JdbcBatchItemWriter<AfterEntity> afterWriter() {
String sql = "INSERT INTO AfterEntity (username) VALUES (:username)";
return new JdbcBatchItemWriterBuilder<AfterEntity>()
.dataSource(dataSource)
.sql(sql)
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.build();
}간단한 예시로 데이터 100개를 순수 테이블에서 테이블로 이동 시킬 때 속도를 비교 해보겠다.
@Bean
public JobExecutionListener jobExecutionListener() {
return new JobExecutionListener() {
private LocalDateTime startTime;
@Override
public void beforeJob(JobExecution jobExecution) {
startTime = LocalDateTime.now();
}
@Override
public void afterJob(JobExecution jobExecution) {
LocalDateTime endTime = LocalDateTime.now();
long nanos = ChronoUnit.NANOS.between(startTime, endTime);
double seconds = nanos / 1_000_000_000.0;
System.out.println("Job 실행 시간: " + seconds + " 초");
}
};
}JPA → 3.7 초
JDBC → 1.3 초
ref
'develop' 카테고리의 다른 글
| Spring Security 권한 여러 개 (학생/강사 테이블 분리된 인증 서비스 구현) (0) | 2025.01.27 |
|---|---|
| 새로운 팀원들 / 코드 리뷰, 테스트 코드를 경험하다. (1) | 2024.12.24 |
| 교차 출처 리소스 공유 CORS 정리 (0) | 2024.09.30 |
| 언제 RDB 대신 MongoDB를 사용할까 (1) | 2024.09.26 |
| CQS (Command Query Separation) (0) | 2024.09.11 |